

Since the last few years, Kubernetes has proved that it is the best container orchestration software on the market. Today, all 3 biggest cloud providers (Amazon, Google and Azure) are offering a form of managed Kubernetes cluster in form of EKS, GKE and AKS respectively. All of those offerings are production-ready, they are fully integrated with other cloud services and they include commercial support.
There is one problem, though, and it is the price. Typically, cloud offerings like this are targeted for big organizations with a lot of money. For example, Amazon Elastic Kubernetes Service costs 144$/mo for just running cluster management (“control plane”), and all compute nodes and storage are billed separately. Google Kubernetes Engine does not charge anything for the control plane, but instances to run nodes at aren’t cheap either – a reasonable 4 GiB machine with only a single core costs 24$/mo. The question is, can we do it cheaper? Since Kubernetes itself is 100% open source, we can install it on our own server of choice. How much we’ll be able to save? Big traditional VPS providers (like OVH or Linode for instance) give out decent machines at prices ranging from 5$/mo. Could this work? Well, let’s try it out!
Setting up the server
Hardware
For running our single-master single-node host we don’t need anything too fancy. The official requirements for a cluster bootstrapped by kubeadm tool, which we are going to use, are as follows:
- 2 GiB of RAM
- 2 CPU cores
- reasonable disk size for basic host software, Kubernetes native binaries and it’s Docker images
For the purpose of this guide I’ll use the minimal recommended specs, however, it should be possible to run it on even less powerful hardware. Let’s create some small virtual server and log in into it through SSH (I’m using DigitalOcean, which gives out 50$ for free for a year if you register through GitHub Student Program):
$ doctl compute droplet create kubernetes-for-poor \ --image ubuntu-16-04-x64 \ --size 2gb \ --region fra1 \ --ssh-keys ee:a4:d1:c3:61:b1:7c:33:ce:49:a0:01:c5:a4:3b:09 (...) $ doctl compute ssh kubernetes-for-poor
In case of further optimization, it’s a good idea to turn off unnecessary services, remove unneeded packages, locales and so on. We’ll go with the default Ubuntu 16.04 configuration that DigitalOcean gave us.
Installing Docker and kubeadm
Here we will be basically following the official guide for kubeadm, which is a tool for bootstrapping a cluster on any supported Linux machine.
First thing is Docker – we’ll install it through the default Ubuntu repo, but generally, we should pay close attention to Docker version – only specific ones are supported. I’ve run into many problems creating a cluster with the current newest version (18.06-*), so I think this is worth mentioning.
$ apt-get update $ apt-get install -y docker.io
And let’s run a sample image to check if the installation was successful:
$ docker run --rm -ti hello-world Unable to find image 'hello-world:latest' locally latest: Pulling from library/hello-world 9db2ca6ccae0: Pull complete Digest: sha256:4b8ff392a12ed9ea17784bd3c9a8b1fa32... Status: Downloaded newer image for hello-world:latest Hello from Docker! This message shows that your installation appears to be working correctly. (...) $
Good. The next step is kubeadm itself – note that the last command (apt-mark hold) will prevent APT from automatically upgrading those packages if a new version appears. This is critical because cluster upgrades are not possible to be done automatically in a self-managed environment.
$ apt-get update && apt-get install -y apt-transport-https curl $ curl -s https://packages.cloud.google.com/apt/doc/apt-key.gpg \ | apt-key add - $ cat <<EOF >/etc/apt/sources.list.d/kubernetes.list deb http://apt.kubernetes.io/ kubernetes-xenial main EOF $ apt-get update $ apt-get install -y kubelet kubeadm kubectl $ apt-mark hold kubelet kubeadm kubectl
Setting up a master node
The next step is to actually deploy Kubernetes into our server. Those 2 basic commands below initialize the master node and select Flannel as an inter-container network provider (an out-of-the-box zero-config plugin). People with experience with Docker Swarm will immediately notice the similarity in init command below – here we specify two IP addresses:
- apiserver advertise address is the address at which, well, apiserver will be listening – for single-node clusters we could put 127.0.0.1 there, but specifying external IP of the server here will allow us to add more nodes to the cluster later, if necessary,
- pod network CIDR is a range of IP addresses for pods, this is dictated by the network plugin that we are going to use – for Flannel it must be that way, period.
Also, we copy some configuration files from their default locations to our home directory, so we don’t have to use kubectl as root later.
$ kubeadm init --apiserver-advertise-address=$PUBLIC_IP \
--pod-network-cidr=10.244.0.0/16
[init] using Kubernetes version: v1.11.2
[preflight] running pre-flight checks
(...)
Your Kubernetes master has initialized successfully!
$ mkdir -p $HOME/.kube
$ sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
$ sudo chown $(id -u):$(id -g) $HOME/.kube/config
$ kubectl apply -f https://raw.githubusercontent.com/coreos/flannel/v0.10.0/Documentation/kube-flannel.yml
Those commands may take a solid few minutes, depending on CPU power and networking speed. To see the progress, a good trick is to use watch command to repeatedly query for all pods on the entire node. Wait until all pods are in the state Running and no more appear in some time.
$ watch kubectl get pods --all-namespaces NAMESPACE NAME READY STATUS kube-system coredns-78fcdf6894-dhfnl 1/1 Running kube-system coredns-78fcdf6894-kf2vl 1/1 Running kube-system etcd-kubernetes-for-cheap 1/1 Running kube-system kube-apiserver-kubernetes-for-cheap 1/1 Running kube-system kube-controller-manager-kuber... 1/1 Running kube-system kube-flannel-ds-lx5ft 1/1 Running kube-system kube-proxy-6nszm 1/1 Running kube-system kube-scheduler-kubernetes-for-cheap 1/1 Running
After a while, they should all be in the state “Running”. Congratulations – the cluster is formally up! One tweak remains, though – by default, kubeadm configures our master node in such a way, that no workloads can be run on it, only regular nodes added later would be able to really run anything. This is done mainly for performance reasons, but here we don’t care, so we need to remove the appropriate label from our master node.
kubectl taint nodes --all node-role.kubernetes.io/master-
And that’s it!
Testing our setup
Testing – pod scheduler
Kubernetes is a really complex piece of container orchestration software, and especially in the context of a self-hosted cluster, we need to make sure that everything has been set up correctly. Let’s perform one of the simplest tests, which is to run the same hello-world image, but this time, instead of running it directly through Docker API, we’ll tell Kubernetes API to run it for us.
$ kubectl run --rm --restart=Never -ti --image=hello-world my-test-pod (...) Hello from Docker! This message shows that your installation appears to be working correctly. (...) pod "my-test-pod" deleted
That’s a bit long command. Let’s explain in detail what are the parameters and what just happened.
When we are using kubectl command, we are talking through the apiserver. This component is responsible for taking our requests (under the hood, HTTP REST requests, but we are using it locally) and communicating our needs to other components. Here we are asking to run an image of name hello-world inside temporary pod named my-test-pod (just a single container), without any restart policy and with automatic removal after exit. After running this command, Kubernetes will find a suitable node for our workload (here we have just one, of course), pull the image, run its entrypoint command and serve us it’s console output. After the process finishes, pod is deleted and the command exits.
Testing – networking
The next test is to check if networking is set up correctly. For this, we will run Apache web server instance – conveniently, it has a default index.html page, which we can use for our test. I’m not going to cover everything in YAML configurations (that would take forever) – please check out pretty decent official documentation. I’m just going to briefly go through concepts. Kubernetes configuration mostly consists of so-called “resources”, and here we define two of them, one Deployment (which is responsible for keeping our Apache server always running) and one Service of type NodePort (which will allow us to connect to Apache under assigned random port on the host node).
$ cat apache-nodeport.yml
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: apache-nodeport-test
spec:
selector:
matchLabels:
app: apache-nodeport-test
replicas: 1
template:
metadata:
labels:
app: apache-nodeport-test
spec:
containers:
- name: apache
image: httpd
ports:
- containerPort: 80
---
apiVersion: v1
kind: Service
metadata:
name: apache-nodeport-test
spec:
selector:
app: apache-nodeport-test
type: NodePort
ports:
- port: 80
$ kubectl apply -f apache-nodeport.yml
It should be up and running in a while:
$ kubectl get pods NAME READY STATUS RESTARTS AGE apache-nodeport-test-79c84b9fbb-flc9p 1/1 Running 0 25s $ kubectl get services NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) apache-nodeport-test NodePort 10.108.114.13 <none> 80:31456/TCP kubernetes ClusterIP 10.96.0.1 <none> 443/TCP
Let’s try curl-ing our server, using a port that was assigned to our service above:
$ curl http://139.59.211.151:31456 <html><body> <h1>It works!</h1> </body></html>
And we are all set!
How to survive in the Kubernetes world outside a managed cloud
Most DevOps people, when they think “Kubernetes” they are thinking about a managed offering of one of the biggest cloud providers, namely Amazon, Google Cloud Platform or Azure. And it makes sense – such provider-hosted environments are really easy to work with, they provide cloud-expected features like metrics based autoscaling (both on container count and node count level), load balancing or self-healing. Furthermore, they provide well-integrated solutions to (in my opinion) two biggest challenges of containerized environments – networking and storage. Let’s tackle the networking problem first.
Kubernetes networking outside the cloud
How do we access our application running on the server, from the outside Internet? Let’s assume we want to run a Spring Boot web hello world. In a typical traditional deployment, we’ll have our Java process running on the host, bound to port 8080 listening to traffic, and that’s it. In case of containers and especially Kubernetes, things get complicated really quickly.
Every running container is living inside pod, which has its own IP address from pod network CIDR range. This IP is completely private and invisible for clients trying to access the pod from the outside world.

The managed cloud solution, in case of Amazon for example, is to create a Service with type LoadBalancer, which will end up creating an ELB instance in your customer account (a whooping 20$/mo minimum), pointing to the appropriate pod. This is, of course, impossible to do in a self-hosted environment, so what can we do? Well, a hacky solution is to use NodePort services everywhere, which will expose our services at high-numbered ports. This is problematic because of those high port numbers, so we slap an Nginx proxy before them, with appropriate virtual hosts and call it a day. This will definitely work, but for such use case Kubernetes provides us something called Ingress Controller, that can be deployed into a self-hosted cluster. Without going into much detail, it’s like installing Nginx inside Kubernetes cluster itself, which makes it possible to control domains and virtual hosts easily through the same resources and API.

Deploying official Nginx ingress is just a few kubectl apply commands away as usual, however, there is a catch – official YAML-s actually are using a NodePort service for Nginx itself! So that won’t really work, because all our applications would be visible on this high port number. The fix to this is to do what Kubernetes explicitly discourages, which is to use fixed hostPort binding for 80 and 443 ports. This way, we’ll be able to access our apps from the browser without any complications. Ingress definitions with those changes can be found at my GitHub, but I encourage you to see the official examples and start from there.
$ kubectl apply -f . $ (...) $ curl localhost default backend - 404 $
If you have a domain name for your server already (or you made a static entry in /etc/hosts), you should be able to point your browser at the domain and see “404 – default backend”. That means our ingress is running correctly, serving 404 as a default response, since we haven’t defined any Ingress resource yet. Let’s use our Nginx Ingress to deploy the same Apache server, using domain names instead of random ports. I set up a static DNS entry in hosts file with name kubernetes-for-poor.test here.
$ cat apache-ingress.yml
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: ingress-test
spec:
selector:
matchLabels:
app: ingress-test
replicas: 1
template:
metadata:
labels:
app: ingress-test
spec:
containers:
- name: ingress-test
image: httpd
ports:
- containerPort: 80
---
apiVersion: v1
kind: Service
metadata:
name: ingress-test
spec:
selector:
app: ingress-test
ports:
- port: 80
---
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: ingress-test
spec:
rules:
- host: kubernetes-for-poor.test
http:
paths:
- path: '/'
backend:
serviceName: ingress-test
servicePort: 80
$ kubectl apply -f apache-ingress.yml
deployment.apps/ingress-test created
service/ingress-test created
ingress.extensions/ingress-test created
$

And pointing your browser at your domain should yield “It works!” page. Well done! Now you can deploy as many services as you like. An easy trick is to create DNS CNAME record, pointing from *.yourdomain.com to yourdomain.com – this way there is no need to create additional DNS entries for new applications.
Kubernetes storage outside the cloud
The second biggest challenge in the container world is storage. Containers are by definition ephemeral – when a process is running in a container, it can make changes to the filesystem inside it, but every container recreation will result in loss of this data. Docker solves it by the concept of volumes, which is basically mounting a directory from the host at some mount point in container filesystem, so changes are preserved.
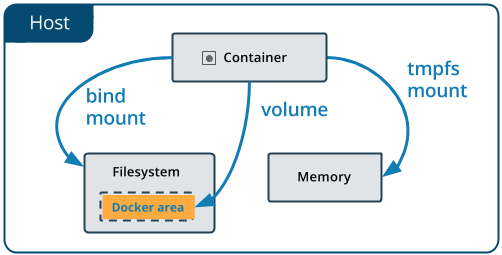
Unfortunately, this by definition works only for single-node deployments. Cloud offerings like GKE solve this problem by allowing to mount a networked storage volume (like GCE Persistent Disk) to the container. Since all nodes in the cluster can access PD volumes, storage problem goes away. If we add automatic volume provisioning and lifecycle management provided by PersistentVolumeClaim mechanism (used to request storage from the cloud in an automated manner), we are all set.
But none of the above is possible on a single-node cluster (outside of managing a networked filesystem like NFS or Gluster manually, but that’s not fun). The first thing that comes to mind is to go the Docker way and just mount directories from the host. Since we have only 1 node, it shouldn’t be a problem, right? Technically true, but then we can’t use PersistentVolumeClaims and we have to keep track of those directories, make sure they exist beforehand etc. There is a better way, though. We can use so-called “hostpath provisioner”, which uses Docker-like directory mounts under the hood, but exposes everything through PVC mechanism. This way volumes are created when needed and deleted when not used anymore. One of the implementations which I’ve tested can be found here, it should work out of the box after just another kubectl apply.
Let’s test it. For this example, we’ll create a single, typical PVC.
$ kubectl apply -f .
$ (...)
$ cat test-pvc.yml
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: test-pvc
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 200Mi
$ kubectl apply -f pvc.yml
$ kubectl get pvc
test-pvc Bound pvc-a5109ca0... 200Mi RWO hostpath 5s
We can see that our claim was fulfilled and the new volume was bound to the claim. Let’s write some data to the volume and check if it is present on the host.
$ cat test-pvc-pod.yml
apiVersion: v1
kind: Pod
metadata:
name: myapp-pod
spec:
containers:
- name: myapp-container
image: ubuntu
command: ['bash', '-c', 'while true; do sleep 1 && echo IT_WORKS | tee -a /my-volume/test.txt; done']
volumeMounts:
- mountPath: /my-volume
name: test
volumes:
- name: test
persistentVolumeClaim:
claimName: test-pvc
$ kubectl apply -f test-pvc-pod.yml
(...)
$ ls /var/kubernetes
default-test-pvc-pvc-a5109ca0-b289-11e8-bc89-fa163e350fbc
$ cat default-test-pvc-pvc-a5109ca0-b289-11e8-bc89-fa163e350fbc/test.txt
IT_WORKS
IT_WORKS
(...)
Great – we have our data persisted outside. If you can keep all your applications running on the cluster, then backups become a piece of cake – all the state is kept in a single folder.
Let’s actually deploy something
We have our single-node cluster up and running, ready to run any Docker image, with external HTTP connectivity and automatic storage handling. As an example, let’s deploy something everyone is familiar with, namely WordPress. We’ll use official Google tutorial with just one small change: we want our blog to be visible under our domain name, so we remove “LoadBalancer” from service definition and add an appropriate Ingress definition.
$ cat wp.yml
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: mysql-pv-claim
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 1Gi
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: wordpress-mysql
spec:
selector:
matchLabels:
app: wordpress-mysql
strategy:
type: Recreate
template:
metadata:
labels:
app: wordpress-mysql
spec:
containers:
- image: mysql:5.6
name: mysql
env:
- name: MYSQL_ROOT_PASSWORD
valueFrom:
secretKeyRef:
name: mysql-pass
key: password
ports:
- containerPort: 3306
name: mysql
volumeMounts:
- name: mysql-persistent-storage
mountPath: /var/lib/mysql
volumes:
- name: mysql-persistent-storage
persistentVolumeClaim:
claimName: mysql-pv-claim
---
apiVersion: v1
kind: Service
metadata:
name: wordpress-mysql
spec:
ports:
- port: 3306
selector:
app: wordpress-mysql
---
apiVersion: v1
kind: Service
metadata:
name: wordpress-web
labels:
app: wordpress-web
spec:
ports:
- port: 80
selector:
app: wordpress-web
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: wp-pv-claim
labels:
app: wordpress
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 20Gi
---
apiVersion: apps/v1 # for versions before 1.9.0 use apps/v1beta2
kind: Deployment
metadata:
name: wordpress-web
spec:
selector:
matchLabels:
app: wordpress-web
strategy:
type: Recreate
template:
metadata:
labels:
app: wordpress-web
spec:
containers:
- image: wordpress:4.8-apache
name: wordpress
env:
- name: WORDPRESS_DB_HOST
value: wordpress-mysql
- name: WORDPRESS_DB_PASSWORD
valueFrom:
secretKeyRef:
name: mysql-pass
key: password
ports:
- containerPort: 80
name: wordpress
volumeMounts:
- name: wordpress-persistent-storage
mountPath: /var/www/html
volumes:
- name: wordpress-persistent-storage
persistentVolumeClaim:
claimName: wp-pv-claim
---
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: wordpress-web
spec:
rules:
- host: kubernetes-for-poor.test
http:
paths:
- path: /
backend:
serviceName: wordpress-web
servicePort: 80
$
The only prerequisite is to create a Secret with the password for MySQL root user. We could easily and safely hardcode ‘root/root’ in this case (since our database isn’t exposed outside the cluster), but we’ll do it just to follow the tutorial.
$ kubectl create secret generic mysql-pass --from-literal=password=sosecret
And we finally deploy.
$ kubectl apply -f wp.yml
After a while, you should see a very familiar WordPress installation screen at the domain specified in the Ingress definition. Database configuration is handled by dockerized WordPress startup scripts, so there is no need to do it here like in a traditional install.
Conclusion
And that’s it! Fully functional single-node Kubernetes cluster, for all our personal projects. Is this an overkill for a few non-critical websites? Probably yes, but it’s the learning process that’s important. How would you become a 15k programmer otherwise?